Retrieval-Augmented Generation (RAG) - Implementation (Part II)

Too much has been spoken, and theory is boring. In this blog, we will go through implementing a RAG-based customer support AI agent using Ollama, NodeJS, and LanceDB.
The full source code used in this blog for demonstration can be found here
We’ll set up a NodeJS project in the following structure:
ai-rag/ ├── db/ ├── knowledge-base/ │ ├── knowledge-base.pdf │ └── knowledge-base.csv │ └── knowledge-base.txt └── node_modules └── index.js └── ingest.js └── utils.js
Implementing a RAG-based system involves the following steps:
- Setting Up the Knowledge Base
- Splitting Documents Into Chunks
- Embedding the Knowledge Base
- Storing Embeddings in a Vector Database
- Retrieving Context for User Queries
- Generating Responses
Setting Up the Knowledge Base
Our knowledge base consists of 3 files in PDF, CSV, and TXT formats. The files include knowledge related to a product or a service for which we are building our AI agent. This internal knowledge base helps enhance LLMs' ability to generate domain-specific responses with high accuracy.
Splitting Documents Into Chunks
To split documents into chunks, we'll use the RecursiveCharacterTextSplitter class from the @langchain/textsplitters package. Splitting documents into chunks helps with efficient retrieval and improves content generation.
import fs from 'fs/promises' import path from 'path' import { RecursiveCharacterTextSplitter } from '@langchain/textsplitters' const splitter = new RecursiveCharacterTextSplitter({ chunkSize: 1000, chunkOverlap: 200, }) const dir = './knowledge-base' const files = await fs.readdir(dir) for (const file of files) { console.log('Processing file:', file) const filePath = path.join(dir, file) const text = await processFile(filePath) if (text) { const chunks = await splitter.splitText(text) for (const chunk of chunks) { // ... } } }
In the above code snippet, we've read the knowledge base directory and processed each file to extract text. Since LLMs inherently do not understand file formats such as PDFs and CSVs, we need to extract and convert their content into plain text before processing. The extracted text is then split into chunks.
Now, let's look at the implementation of the processFile() method in the utils.js file to see how we've extracted and converted the knowledge base from various formats into plain text.
import { promises as fs } from 'fs' import { extname } from 'path' import pdfParse from 'pdf-parse/lib/pdf-parse.js' import csvParser from 'csv-parser' import { createReadStream } from 'fs' async function readTextFile(filePath) { return await fs.readFile(filePath, 'utf-8') } async function readCsvFile(filePath) { const rows = [] await new Promise((resolve) => { createReadStream(filePath) .pipe(csvParser()) .on('data', (row) => rows.push(Object.values(row).join(' '))) .on('end', resolve) }) return rows.join('\n') } async function readPdfFile(filePath) { const dataBuffer = await fs.readFile(filePath) const data = await pdfParse(dataBuffer) return data.text } export async function processFile(filePath) { const ext = extname(filePath).toLowerCase() if (ext === '.txt') return await readTextFile(filePath) if (ext === '.csv') return await readCsvFile(filePath) if (ext === '.pdf') return await readPdfFile(filePath) return '' }
You can apply a similar approach when processing other types of files. For example, if you need to process image files, you must first extract their text content.
Embedding the Knowledge Base
Once the documents are split into smaller chunks, we will convert each chunk into an embedding using Ollama's JavaScript library. We'll also use the same library to interact with our locally running LLM.
import { Ollama } from 'ollama' const ollama = new Ollama({ host: 'http://localhost:11434' }) const chunks = await splitter.splitText(text) for (const chunk of chunks) { const response = await ollama.embeddings({ "mxbai-embed-large", prompt: chunk, }) const embedding = response.embedding }
mxbai-embed-large is an embedding model that is used to generate high quality text embeddings.
Storing Embeddings in a Vector Database
These embeddings can be stored in a vector database - we will use LanceDB in our demonstration. Storing embeddings in a vector database allows us to perform similarity searches and enables RAG systems to find the most relevant chunks based on the user's query.
const dbPath = path.resolve('./db') const db = await connect(dbPath) const table = await db.createTable( 'knowledge_vectors', [{ vector: embedding, text: "dummyPrompt", source: 'dummy.json' }], { writeMode: 'overwrite' } ) const embedding = response.embedding await table.add([{ vector: embedding, text: chunk, source: file }])
In the above code snippet, we are creating the knowledge_vectors table with a dummy record to ensure that the table schema is properly initialized. Once we generate an embedding for a chunk of data, we're also adding the record to our table using table.add([{ ... }]).
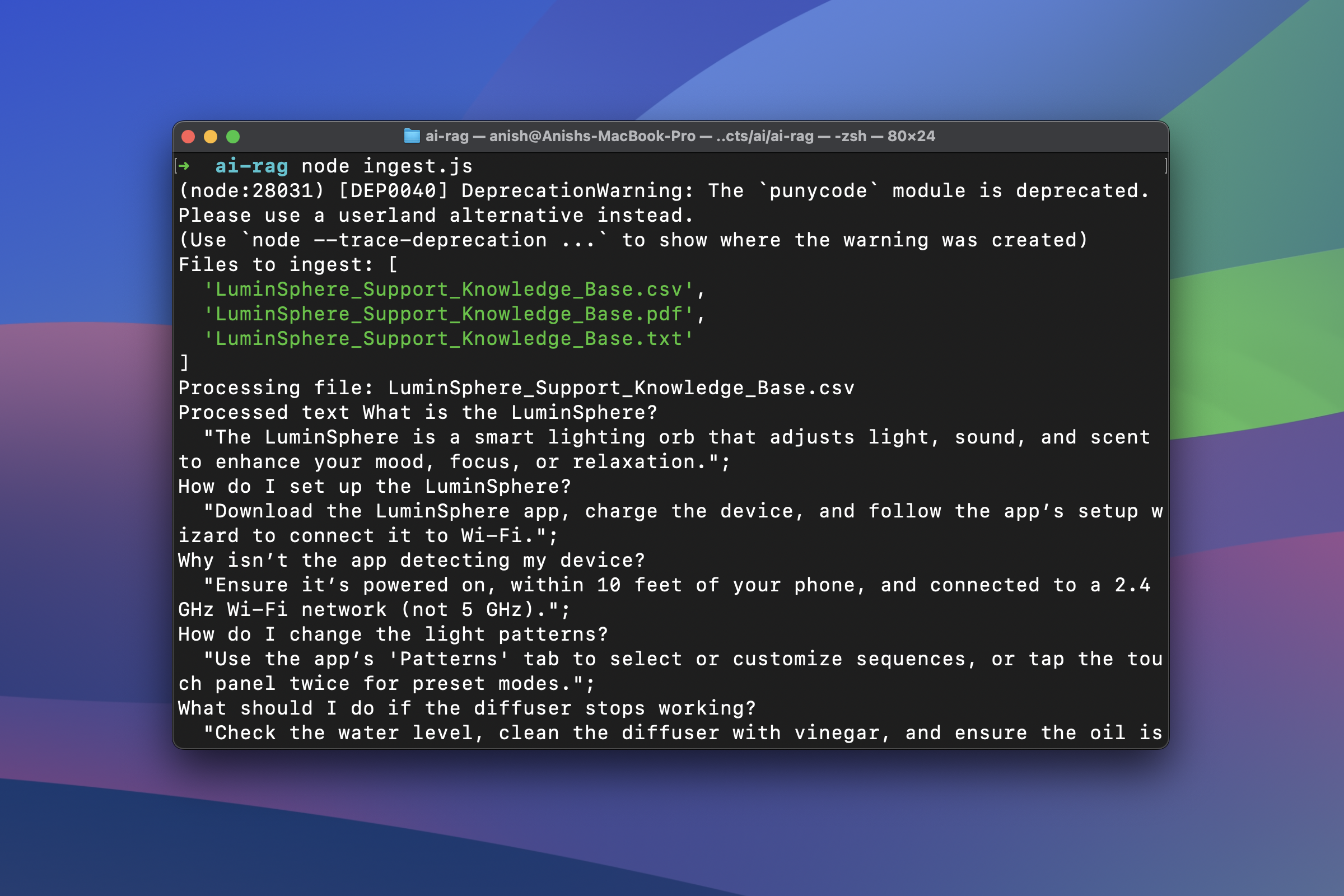
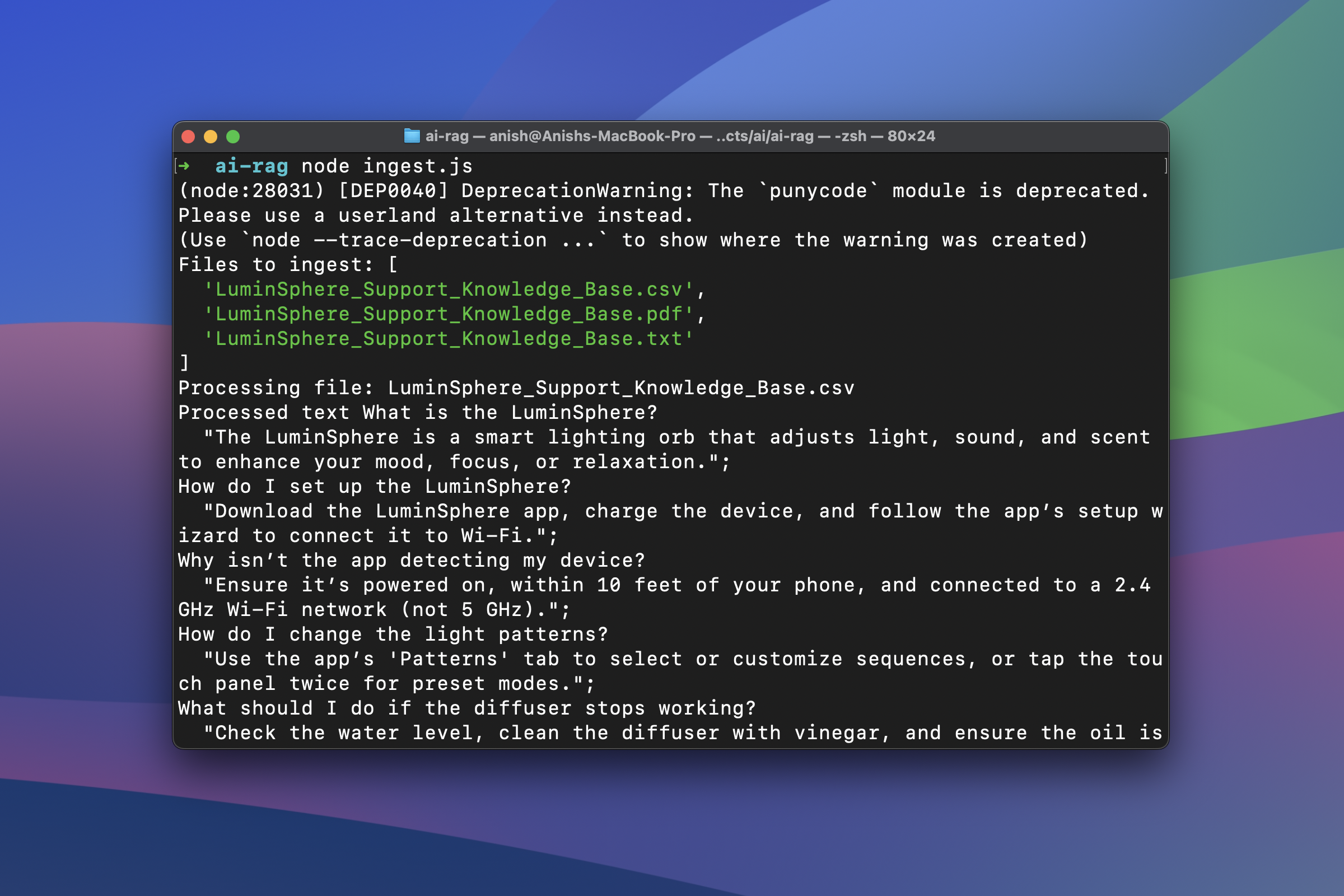
The overall process of setting up the knowledge base, splitting documents, generating embeddings, and storing them in a vector database falls under the data ingestion process. You can review the complete data ingestion logic (ingest.js) here.
Once we've prepared our knowledge base and implemented the ingestion logic, we can run the data ingestion using node ingest.js. This will split large documents into chunks, create embeddings for the split chunks, and store them in a vector database for efficient retrieval.
Retrieving Context for User Queries
Now comes the main part of retrieving relevant context that is related to the user's query, so that the LLM can generate an accurate and domain-specific response.
import { Ollama } from 'ollama' async function processQuery(query) { const ollama = new Ollama({ host: 'http://localhost:11434' }) const dbPath = path.resolve('./db') const db = await connect(dbPath) const table = await db.openTable('knowledge_vectors') const queryEmbedding = await client.embeddings({ 'mxbai-embed-large', prompt: query, }) const results = await table.vectorSearch(queryEmbedding).limit(2).toArray() const context = results.map((r) => r.text).join('\n\n') console.log('Retrieved Context:', context) }
In the provided code snippet above (index.js), we'll generate an embedding of the user's query using the embedding model mxbai-embed-large. We need to use the same embedding model that was used to store the embeddings generated from the chunks of the knowledge base.
Generating Responses
Once the embedding of the user's query is generated, we perform a vector search in the knowledge_vectors database table to find the most similar data.
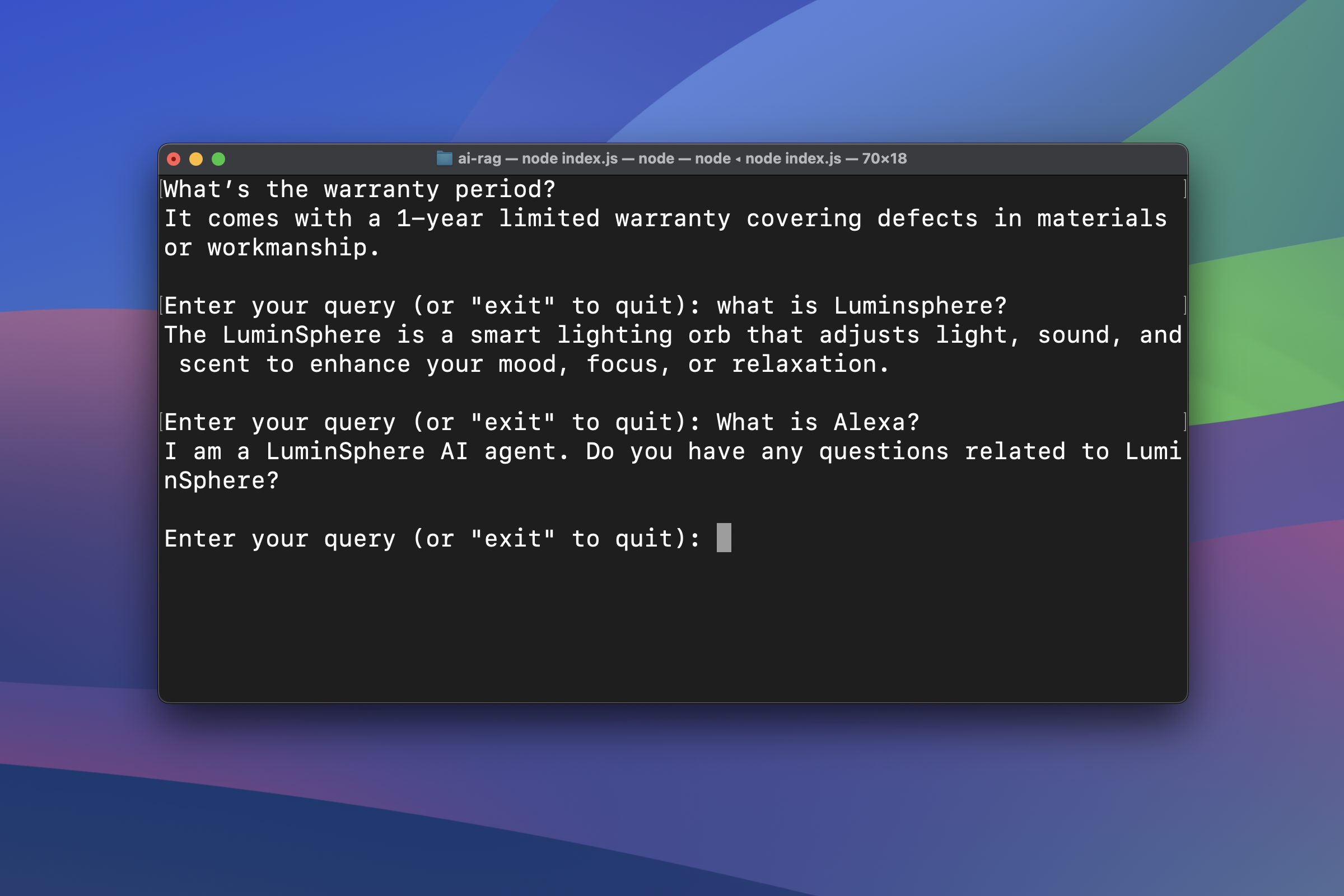
When asked, "What’s the warranty period?", it was able to retrieve the following context:
... 15. What’s the warranty period? It comes with a 1-year limited warranty covering defects in materials or workmanship. ...
Now comes the final part of RAG: generating a response using the prompt that includes both the user's query and the retrieved context.
async function generateResponse(query, context) { const ollama = new Ollama({ host: 'http://localhost:11434' }) const prompt = ` You are a helpful AI agent specialized as customer service representative for LuminSphere with the following information: ${context} Your task is to answer the question based on the information above. Question: ${query} ` const response = await ollama.generate({ model, prompt }) console.log(response) }
That's it! We have successfully implemented a RAG-based system using NodeJS, Ollama, and other libraries. To view the full source code, you can visit the repo. The repo contains examples of both Ollama and OpenAI implementations.
