Retrieval-Augmented Generation (RAG) - Introduction (Part I)
In our previous blog, we briefly discussed AI agents and implemented an intelligent AI agent that utilized a knowledge base to assist users with customer support.
However, the implementation has some limitations, particularly in retrieval efficiency and scalability. This is mainly because the entire knowledge base is sent with every request, even when only a specific portion is needed.
Introduction to Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) is a technique or framework used in AI and Natural Language Processing (NLP) to generate contextually relevant responses to the end user by retrieving relevant information from a variety of data sources.
RAG bridges the gap between Large Language Models (LLMs) and their limitations, such as knowledge cutoff, static understanding, and hallucination.
LLMs are limited to their last training data; they can't learn new information dynamically unless retrained. When LLMs lack data, they may generate incorrect or misleading responses.
To improve contextual accuracy, a technique called Fine-Tuning is also used, in which a pre-trained model is further trained on smaller, more specific datasets.
Therefore, RAG techniques are applied to overcome the limitations of LLMs by providing an external knowledge base.
Retrieval-Augmented Generation (RAG) Example in Customer Support
For example, in customer support, LLMs often struggle to generate real-time, accurate, and domain-specific responses.
In such situations, we can create a knowledge base that includes product-specific FAQs, forum conversations, documentation databases, and internal discussions, and use this information while generating a response to support query.
As a result, LLMs will be able to generate accurate and domain-specific responses with the help of RAG.
How Retrieval-Augmented Generation (RAG) Works?
Retrieval, augmentation, and generation are key components of RAG.
The RAG process begins with retrieving relevant data, then augmenting the LLM's understanding with the retrieved data, and finally generating the response based on both the pre-trained and retrieved data.
Retrieval-Augmented Generation (RAG) Pipeline
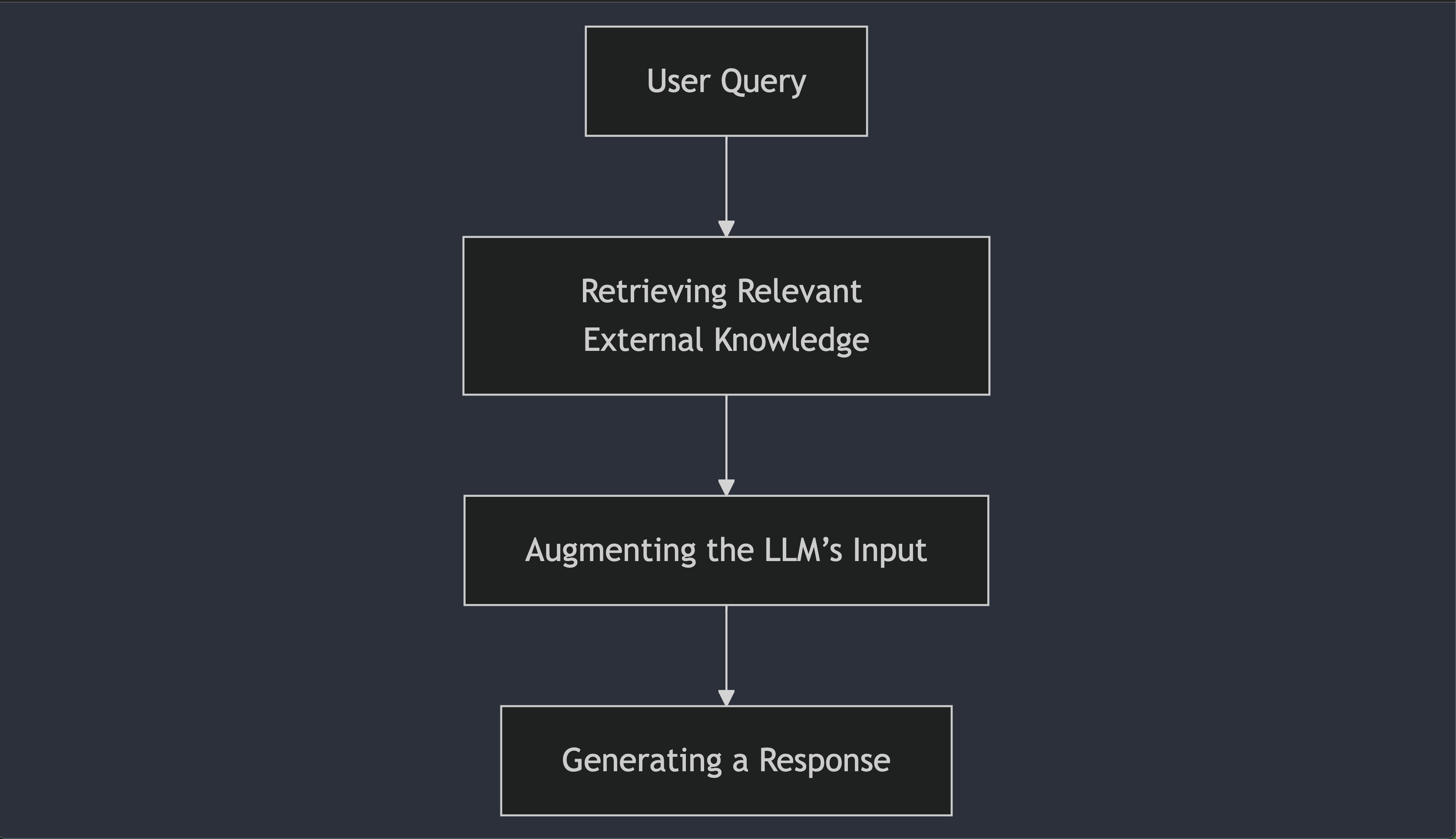
User Query
The process starts with user's query. For e.g.: How do I activate my account?
Retrieving Relevant External Knowledge
The system retrieves relevant information from an external knowledge base based on the user's query. It might identify pieces of data such as, To activate an account...
Augmenting the LLM’s Input
The retrieved information is then augmented with the user's query. The combination of the user's query and the retrieved knowledge together forms the prompt for the LLM. The prompt may look like: How do I activate my account? [To activate an account ...]
Generating a Response
The LLM generates a response based on both the user's query and the retrieved knowledge.
Tokens and Context Window
Tokens are the fundamental units of input and output for LLMs. They can be a character, a word, or a subword. LLMs use tokenization to process text by breaking it into tokens.
Similarly, the context window refers to the amount of data (measured in tokens) that the model can process at a given time when generating a response.
The context window consists of the user's input (prompt), retrieved knowledge (RAG), the model's internal memory (if applicable), and the generated response.
We'll discuss tokenization and the context window in detail in another blog post.
Token Limitations in LLMs
Since machines are bound by hardware specifications, LLMs have a fixed context window and can process only a limited number of tokens at a time.
If an input exceeds the context window's capacity, some tokens may be ignored or truncated, increasing the risk of AI hallucination due to the loss of important information. This can impact the quality and accuracy of the generated responses.
How RAG Helps Overcome the Context Window Problem
Instead of feeding the entire knowledge base, which may contain irrelevant information or data unrelated to the user's intended query, RAG helps by dynamically retrieving and feeding only the relevant information from the knowledge base.
Core Components of Retrieval-Augmented Generation (RAG)
Retrievers, embeddings, vector databases, and chunking strategies are the core components of the Retrieval-Augmented Generation (RAG) pipeline.
Retrievers
Retrievers are responsible for retrieving relevant information from the knowledge base based on the user's query. They typically use semantic search to find information that is contextually related to the user's query.
Embeddings
Since machines operate at a lower level, tokens are converted into numerical representations, and these numerical representations of tokens are called embeddings.
Embeddings help capture the semantic meaning and context of words, enabling LLMs to understand the relationships between words and connect different pieces of information.
This ability to contextualize meaning allows models to handle polysemy (the multiple meanings of words) effectively.
As a result, LLMs can generate more accurate, precise, and contextually appropriate responses to a user's query, even in complex situations.
Vector Databases
Vector databases are specialized databases that help manage embeddings (vectors). They enable fast lookups and similarity searches across large sets of embeddings, ensuring the retrieval of the most relevant information.
ChromaDB and FAISS are some examples of vector databases.
Chunking Strategies
Chunking strategies are methods of breaking down large datasets or knowledge bases into smaller, more manageable pieces. Chunking is a crucial step in RAG and enhances the efficiency of LLMs.
That's it! A lot of theory about RAG. Let's take a break, and we'll be back in another blog with a RAG implementation using Ollama, NodeJS, and LanceDB.
AI Agents - Introduction and Customer Support AI Agent Example
In this blog, we'll discuss AI Agents and implement a Customer Support AI Agent with a custom knowledge base using Ollama and NodeJS.
Retrieval-Augmented Generation (RAG) - Implementation (Part II)
In this blog, we will implement a Retrieval-Augmented Generation (RAG) system using Ollama, NodeJS, and LanceDB.